


Clio's Blind Spot
Why Clio ought to be reporting on API and business usage, not just individual users



Anthropic’s “Claude insights and observations” (Clio) provides anonymized data from one million Claude.ai Free and Pro conversations. Their blog post and technical paper about the tool provide click-worthy statistics on “the most common high-level use cases on Claude.ai (coding, writing, and research tasks) as well as patterns that differ across languages (e.g., conversations in Japanese discuss elder care and aging populations at higher than-typical rates.)” This is interesting stuff.
It could also be a huge boon to AI safety. Anthropic notes:
“This isn’t just a matter of curiosity, or even of sociological research. Knowing how people actually use language models is important for safety reasons: providers put considerable effort into pre-deployment testing, and use Trust and Safety systems to prevent abuses. But the sheer scale and diversity of what language models can do makes understanding their uses—not to mention any kind of comprehensive safety monitoring—very difficult.”
We agree. As we’ve written, only testing AI models in the lab pre-deployment is a bit like limiting auto safety to crash testing vehicles before putting them on the market, while ignoring all the safeguards needed on the road, where real drivers use and abuse their vehicles’ capabilities. Understanding how a product is used in practice, post-deployment, is essential.
Unfortunately, the initial report gives insight into only a small fraction of the overall usage of Claude. Tucked away in a footnote on page 2 of the technical paper, the authors note “Because we focus on studying patterns in individual usage, the results shared in this paper exclude activity from business customers (i.e. Team, Enterprise, and all API customers.)” The omission of API and other corporate usage is a huge blind spot. This could be because the data privacy agreements for business versus personal accounts are different, or simply because they do not want to inspire pushback from the businesses who work with them. Corporate accounts are more likely to input commercially sensitive information to the model and could react negatively to usage trends being shared publicly.
The paper does address these privacy concerns up front:
First, users share sensitive personal and business information with these systems, creating a fundamental tension between privacy protection and the need for providers to understand how their systems are being used. Second, having humans review conversations can raise ethical concerns, due to the repetitive nature of the task and the potentially distressing content reviewers could be exposed to. Third, providers face competitive pressures not to release usage data even if it would be in the public interest, as such data could reveal information about their user bases to competitors. And finally, the sheer scale of the data makes manual review impractical—millions of messages are sent daily, far more than any human team could meaningfully analyze.
However, if Clio’s privacy-preserving technology is as good as they say it is, it should be possible to preserve the privacy of Anthropic’s business customers in much the same way as it does the privacy of their individual users, as long as they follow the same aggregation methods that prevent the identification of individual customer data. It would be fascinating to see comparisons in usage between users of Anthropic’s public facing systems and its APIs. I’d bet there are some substantial differences.
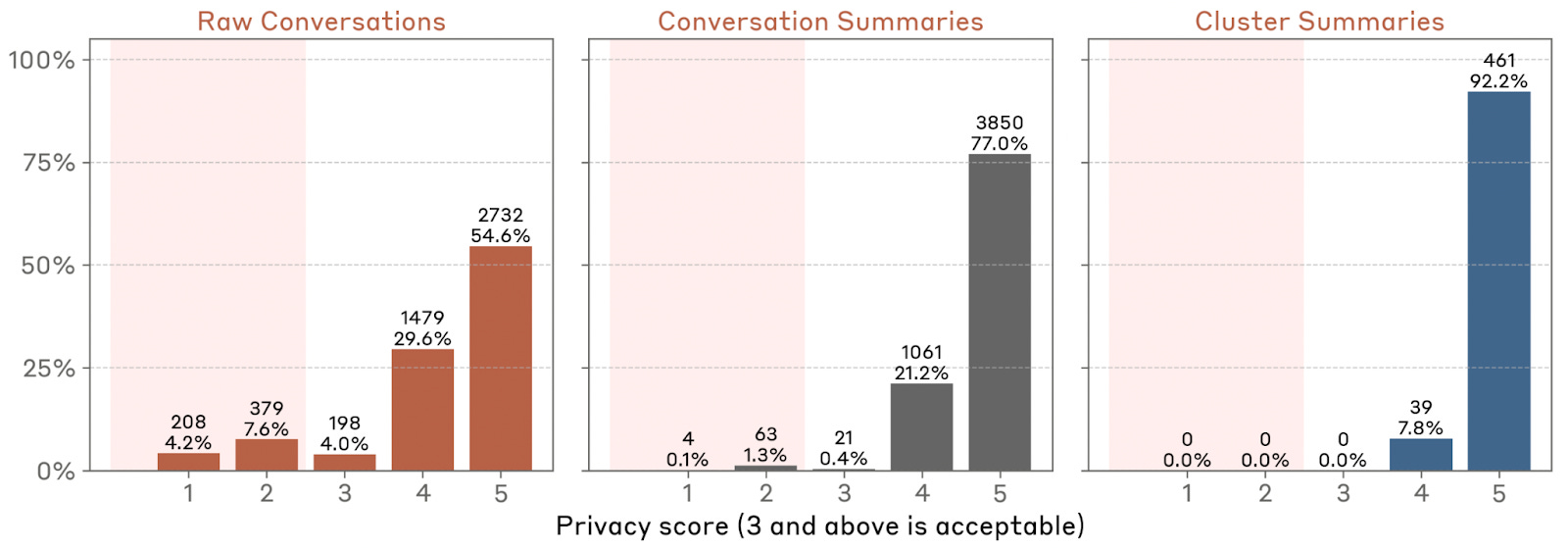
Note: Figure 5 from paper (pg.7) showing how data is processed to ensure subsequent data analysis and auditing is privacy preserving. Anthropic is asking the model to summarize the conversations over and over again at different levels of detail (from conversation to cluster to summary).
But that’s just curiosity, and not essential for AI safety. What is essential is that Anthropic itself uses such data “to make our systems safer by identifying coordinated attempts to abuse our systems, monitoring for unknown unknowns during critical periods like launches of new capabilities or major world events, and improving our existing monitoring systems.” And they are. As the paper notes, “For safety investigations, we also run Clio on a subset of first-party API traffic, keeping results restricted to authorized staff.” But it shouldn’t end there. Summarized results should be disseminated more widely.
Because of the uncertainty of this entire field, and some of the fear mongering about superintelligence surrounding the early AI hype, AI risks over-regulation. I spoke recently with the head of regulatory affairs for a major AI vendor (not Anthropic) who noted that, with all their resources, they were still having trouble keeping up with the onslaught of AI regulation. It’s not just major bills like the EU AI Act (compliance is complex enough to justify an entire O’Reilly book!) but hundreds of local jurisdictions that are putting their oar in, often blindly. Helping regulators to understand the real risks of AI, including from business users, ought to be a major focus of projects like Clio. As I noted in the piece that gave birth to the AI Disclosures Project, you can’t regulate what you don’t understand. One of our most important goals at our project is to help companies work with regulators to standardize best practices for AI management and safety in the same way that Generally Accepted Accounting Principles standardize accounting and financial auditing. Having hundreds of differing regulatory regimes is a recipe for chaos.
There are several important lessons for regulators in Anthropic’s work on Clio:
Using systems such as Clio to monitor actual usage is a critical part of any AI safety regime, a best practice that is likely followed by most (but possibly not all) leading AI providers and application developers. Having a standard set of privacy-preserving tools, and making sure that all companies are using them, would be a fabulous addition to the toolbox.
Assessing the adequacy of such monitoring ought to be an essential part of any AI safety audit. As the paper notes, results from their “use of Clio on other traffic to support our safety efforts (e.g., monitoring during high-stakes events, after new capabilities such as computer use are launched, or other times of increased uncertainty) … are restricted to a small number of authorized staff and are not included in this paper.” But that doesn’t mean that it shouldn’t also be accessible to auditors, much as intimate details of a company’s financial operations are restricted to a small number of authorized staff, but are also periodically inspected by outside auditors. For most businesses, these auditors are licensed and highly trained private third parties. In highly regulated regimes like finance, these auditors may be regulatory supervisors embedded full time in the business.
Any system of disclosures that does not include the activities of third party developers and business users is missing an essential part of the risk landscape. Anthropic recently reported that only 15% of its revenue came from Claude chatbot subscriptions, while the remaining 85% came from third party API (60-75%), direct API (10-25%), and professional services (2%). We don’t have access to direct usage numbers, but based on the revenue numbers, it seems as if the majority of usage is from business customers, who are not included in Clio. As the AI marketplace matures, an even greater percentage of activity is likely to run through third party developers. The relatively centralized API providers are a natural place to understand and detect bad behavior.
Disclosure is not all or nothing. While some data may be disclosed to the public, other data may follow a regime similar to that for accounting and financial auditing, in which deeper information is disclosed to auditors. And particularly high-risk information may be disclosed to regulators.
We’d love to see a robust set of monitoring tools like Clio made available to all AI model developers, and an effort to reach agreement among those developers about what should be monitored, and what should be shared with whom. The AI developer community still has an opportunity to get ahead of ill-advised regulation, but only by becoming more proactive about disclosing what they monitor and manage in their AI systems as deployed, and by agreeing on a model of progressive disclosure to those with legitimate interests in what these tools can reveal.
 | A guest post by
|
 | A guest post by
|