


Is Copyright Dead? (Weekly Roundup)
What the latest Copyright Office report means for AI's training & inference, OpenAI's new head of monetization, Steve Bannon on AI regulations (bonus), and more.



Good morning! This week’s roundup covers: the conspicuous firing of a top copyright official, Google forcing publishers to participate in AI Overviews, OpenAI’s new CEO of Monetization (oops, I mean “Applications”), Claude’s mega-long system prompt, and efforts to control online scams.
Copyright under fire. The Trump administration fired the head of the U.S. Copyright Office, Shira Perlmutter, a day after the office released a report on fair use in AI training. The prepublication version of the report concluded that not all AI usage is protected under fair use but recommends market-based solutions for now:
Making commercial use of vast troves of copyrighted works to produce expressive content that competes with them in existing markets, especially where this is accomplished through illegal access, goes beyond established fair use boundaries.
[…]
Given the robust growth of voluntary licensing, as well as the lack of stakeholder support for any statutory change, the Office believes government intervention would be premature at this time. Rather, licensing markets should continue to develop, extending early successes into more contexts as soon as possible.
Chat GPT Is Eating the World notes in their analysis of the draft report that the Office also endorses the argument that not all AI training is protected under fair use, since it affects the value of the original copyrighted work. From the official report:
The speed and scale at which AI systems generate content pose a serious risk of diluting markets for works of the same kind as in their training data. That means more competition for sales of an author’s works and more difficulty for audiences in finding them.
This is somewhat controversial, as this argument has yet to be recognized by any court in a copyright case. If this report becomes official, it could open up a new avenue for litigation against model developers. That’s a big if, though.
Perlmutter’s firing most likely indicates hostility by the Trump administration against any sort of rapid-fire copyright enforcement on AI companies. This comes right after industry leaders, including OpenAI and Google, directly requested that the U.S. protect their right to freely train their models on copyrighted data.
We believe that compensation for content creators is not only fair, but important to maintaining a healthy ecosystem for creators and AI developers alike. Without fair compensation, publishers will suffer, and AI models will ultimately be left without valuable up-to-date information to inform their responses. As the U.S. Copyright Office noted, voluntary licensing has already begun. But without the stick of copyright law being available to private parties through the courts, it’s unlikely that content licensing agreements will magically arise from market forces alone.
OpenAI’s new CEO of Monetization. OpenAI appointed a new “CEO of Applications”, Fidji Simo, who was previously CEO of Instacart, where she was expert at monetization. To support these efforts OpenAI recently acquired Windsurf for $3 billion, a popular AI-powered code editor. These changes demonstrate the burgeoning interest in AI applications, as expensive foundation models multiply in the market and have yet to make a profit. Applications built on top of the foundation models are relatively cheap to make, more immediately profitable, and are competing in a less capital intensive market with potentially greater consumer lock-in (FT graph below). Although sales are growing much faster than with previous technologies, profitability remains a concern.
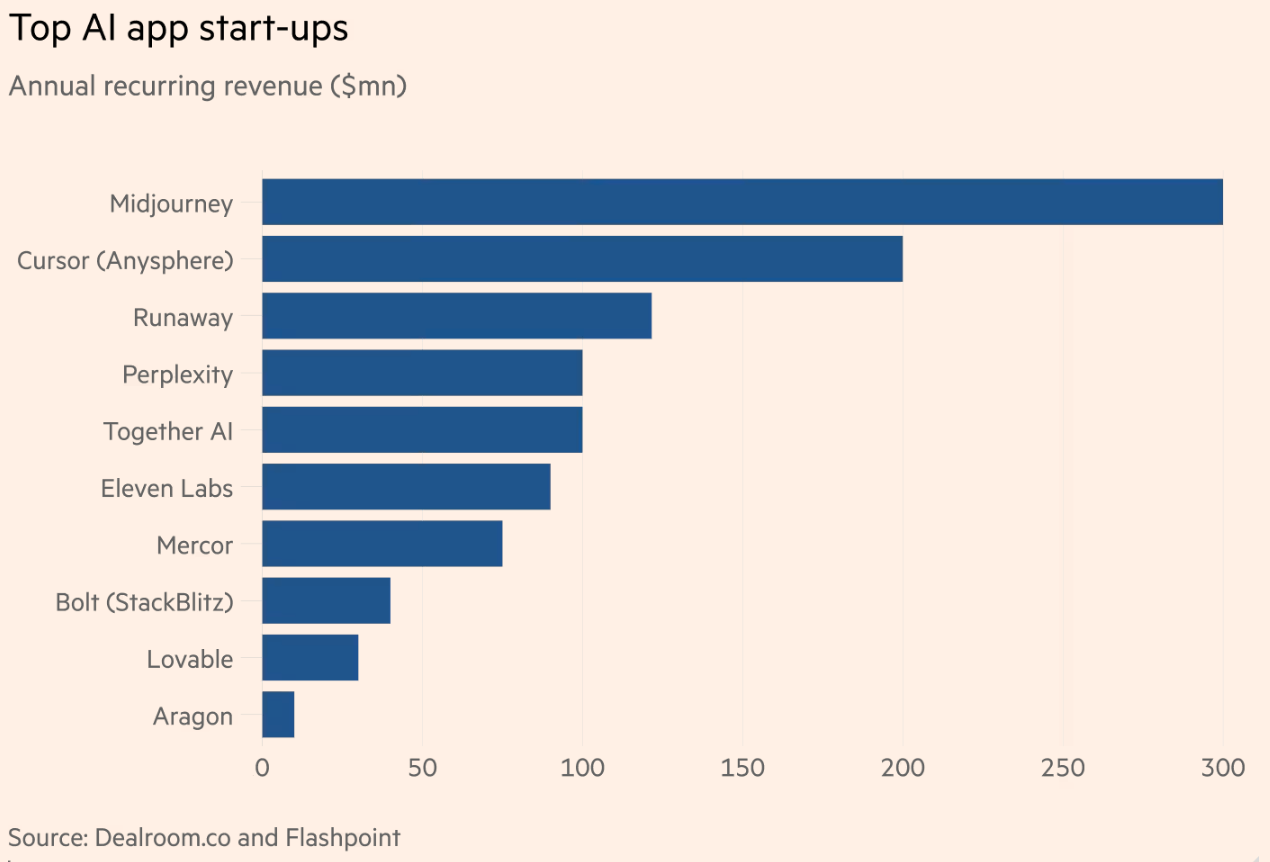
Source: Financial Times, April 14 2025. Simo’s appointment likely foreshadow’s OpenAI incorporating ads into ChatGPT’s results, and comes alongside OpenAI’s new shopping vertical in GPT, and more carousel images being placed in results. Simo introduced ads to Instacart, and was heavily involved in advertising at Meta while a top executive there. And although OpenAI has yet to introduce any advertising in their products, they continue to operate at a significant loss and will need to find other sources of revenue. That raises the recurring issue of how to manage advertising markets online…but now in potentially hyper-persuasive and personalized contexts.
Probably the quickest way to reduce a range of harms online today is to properly regulate platforms’ advertising algorithms and inventory, where many widely distributed scams originate. That’s why EU member states are pushing for a rule change to ensure tech giants shoulder responsibility for online fraud that they facilitate through their advertising content. Currently, Big Tech do not need to check the legitimacy of advertisers before allowing their ads to be posted. Limiting harms from AI in the near future is likely to, similarly, turn on questions of safeguards on paid content promotion, rather than just organic content (as is the current debate). The MIT AI Incident Tracker already shows that 25% of recorded AI incidents in 2024 — the largest share — were from “Frauds, scams, and targeted manipulation.”
More than just a model: Claude’s system prompt. A look at Claude’s system prompt is a reminder that the major AI “model developers” already offer more than just a model to their customers. A system prompt is the hidden set of instructions provided to the model, not seen by the user, and used by the model to help process the user’s request. While there are other methods for steering a model’s behavior, the prompt is the final opportunity for the developer to set the system’s settings. Drew Breunig wrote up an interesting analysis of the 16,000+ word system prompt for Anthropic’s model Claude.
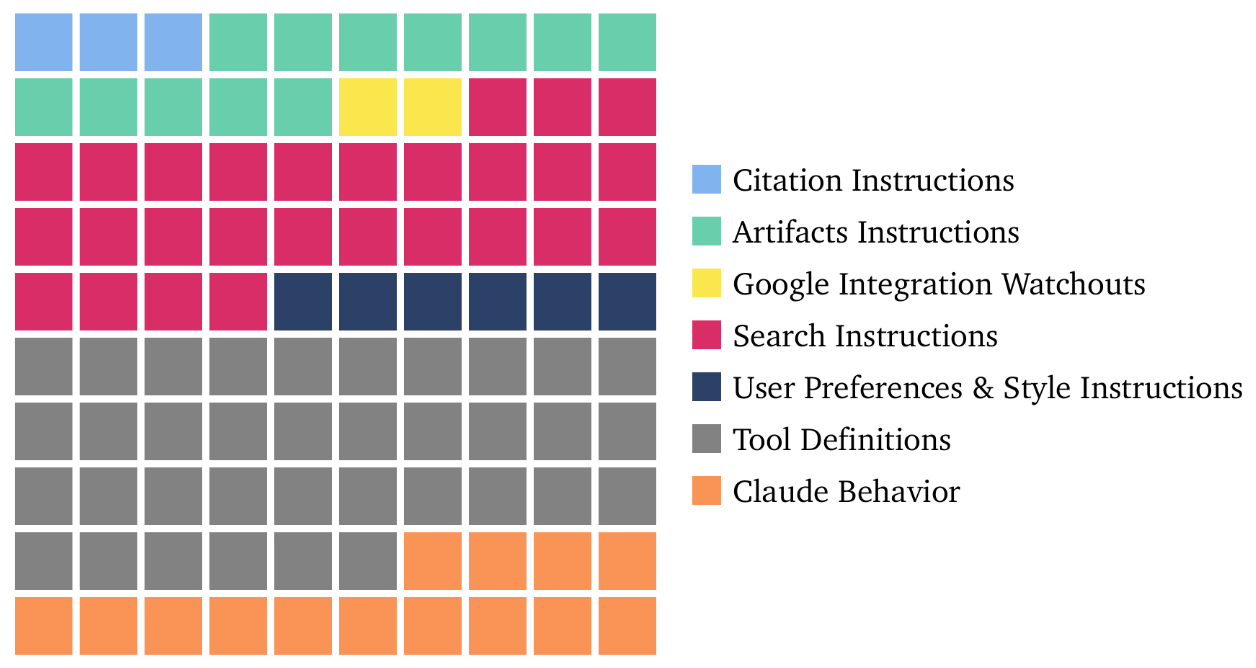
Source: dbreunig.com He shows that Claude’s prompt consists mainly of instructions on how to use various tools (grey boxes), including search (red boxes), that Claude has access to. Scaffolding and tools are important not just to Claude’s system prompt but to its in-market capabilities and utility. The level of detail in the prompt shows that Anthropic has created more than just a powerful model — but an application full of useful tools combined into a single seamless user experience. This also highlights a growing gap between what AI companies test for in their evals, and what customers are interacting with — something far more capable than a lone model!
As a humorous aside, there seem to be many “hotfixes” thrown into the system prompt too: “If Claude is asked to count words, letters, and characters, it thinks step by step before answering the person. It explicitly counts the words, letters, or characters by assigning a number to each. It only answers the person once it has performed this explicit counting step.” This is a fix to the classic “count the Rs in strawberry” question.Forced to ground Google’s AI search answers: uncompensated IP? More juicy bits of information are being revealed in Google’s remediation hearings after a judge declared that Google has an illegal monopoly on search. New documents show that Google essentially strong-armed publishers into making their content available for Google’s AI Overviews (AIO) in search results. Google maintains a separate web crawler that scrapes data to be used for training their Gemini model; but the web crawler that they use for AIO is the same as the one that indexes Search (“Googlebot”). This means that publishers would have to remove themselves from Google search results (which is effectively disappearing from the internet) if they don’t want to be part of AIO.
As discussed in previous weekly roundups, the introduction of AIO, and AI search in general, has precipitously dropped the amount of clicks going to publishers (according to data from Matthew Prince at CloudFlare), which in turn has tanked advertising revenue. Publishers are in a bind: release their information to be processed and spat out at the top of a Google search in the form of a grounded AI answer — with no revenue earned unless users click on a link to their cite (if one is provided); or be left off of Google’s search results entirely. All the more reason to take fair compensation for training data seriously.
Bonus ContentSteve Bannon on AI regulation in the U.S. Bannon, representing the populist wing of MAGA and the Trump Administration (despite not being in it), gave a very clear — albeit inconsistently argued — interview with the Financial Times’ Edward Luce, in which he repeats his views on AI. On the topic of regulation, he argues that: “Right now, a nail Salon in Washington, D.C., has more regulations than these four guys running wild on artificial intelligence right now.” You know what they say about broken clocks? For now though, it seems as if Bannon’s desire for greater domestic corporate AI regulations are not making it into the administration’s policies.

Source: Financial Times One wonders if his comments portend more aggressive domestic FTC and DoJ enforcements on these issues, even as U.S. AI companies are provided with much greater latitude by the administration to act abroad — much to Bannon’s chagrin no doubt. Conflicting domestic and international needs on AI — to protect domestic welfare by chopping down giant corporations, but wanting to also facilitate greater international competitiveness abroad for U.S. corporates through allowing them to grow in size and capabilities — are not new to U.S. antitrust considerations. In many ways the international pull, towards permitting greater corporate efficiency & scale, underpinned the weakening of America’s domestic antitrust agenda during the 1980s. For now though, the administration seems happy to entertain more aggressive domestic antitrust enforcement, even when it impedes AI companies from competing at scale abroad.


Thanks for reading! If you liked this post subscribe now, if you aren’t yet a subscriber.
 | A guest post by
|
 | A guest post by
|