
OpenAI’s Telemetry
Metrics, logs, and traces keep AI systems healthy. But they should also be at the centre of holding AI companies accountable.


Why Telemetry should be at the Centre of AI Governance and Oversight
Yesterday, with enough prompting finesse, I discovered that OpenAI’s models can expose the structured user data that they maintain — metrics created from user interactions and other telemetry including conversation logs and traces. After successfully prompting the system, I wanted to share what it revealed about my own usage patterns. This builds on Katharine Jarmul (author of O’Reilly's “Practical Data Privacy”) and Simon Willison.
As far as I can see, telemetry (logs, traces, metrics) matters for regulatory oversight for four key reasons:
First, it can help highlight the underlying business model, which may not always be obvious. Telemetry shows what metrics companies track about user profiles and engagement, providing outsiders insight into a system’s optimization goals. Just as airlines track seat capacity and occupancy, an AI system monitoring conversation length and turn frequency might eventually optimize for time spent on the platform, if their business model involves sponsored content in outputs.
Second, it indicates the system’s health when the relevant metrics are tracked. Third, it shows actual safeguards in place, not just promised ones, along with their efficacy. Fourth, it identifies risks the system detects in real-time, not just the hypothesized ones that abstracts from real-world usage.1
Most importantly, telemetry represents what companies consider most worth tracking internally. These aren’t statistics invented by bureaucrats – they’re live production metrics reflecting firm-specific and industry risks, efficiency ratios, and system health indicators. This alone makes them valuable for regulators building market monitoring obligations or meaningful AI auditing processes. (So if you’re a firm wanting to meet the monitoring obligation (3.5) in the EU’s General-Purpose AI Code of Practice, why not offer up parts of your telemetry instead through a secure, limited visibility, endpoint?)
As telemetry becomes standardized through efforts like OpenTelemetry, opportunities emerge for cross-system comparison and data portability to auditors. This standardization could transform how we approach AI policy obligations around disclosures, auditing, and post-deployment monitoring – providing concrete content to buzzwords that often lack substance.
What is Telemetry in AI Systems?
Telemetry is the nervous system of modern technology platforms, consisting of three components — logs, traces, and metrics:
Logs are structured records of events. Examples are a timeout log recording rate-limit hits; a retrieval log for RAG pipelines capturing document ID, score, and rank for URLs visited during internet searches, enabling LLM content consumption being traced back to its sources; and guardrail logs that record which content filters were triggered during conversations, violation categories, and actions taken — proving safety systems actually work in production.
Traces track system behavior across multiple “spans” (individual units of work), providing end-to-end visibility into a request’s processing as it moves through different parts of the system.
For an internet search query like "What are the latest developments in quantum computing this week?" a trace might show the AI system breaking down the query into two web searches:

Each sub-process — like a “bing-api-call” — is called a span and shows how the system actually operates. After breaking down the search request into two search queries, the trace then shows the system removing duplicate sources, prioritizing sources, and preparing the answer along with citations:

The analytics and logging traces, along with the search statistics trace-level metadata might look something like this:


These are all part of the same single trace.
We can see how this analytics and logging, as part of the single trace, can provide not just the firm processing the request with valuable insight into the accuracy and behaviour of the system, but also the business- or end-user. In other words, a trace provides transparency into how a system actually works, at least in terms of the tasks and steps it breaks down a single user request into.
3. Finally, metrics are quantitative measurements covering an AI system’s performance (inference latency, model accuracy), resources (GPU utilization, memory consumption), business KPIs (cost per request, user satisfaction), and AI-specific health indicators (model drift, hallucination rates). The hundreds of possible measurements reflect what matters most to the business.2
In the same way an ordinary business optimizing for profit will use different metrics to assess how efficient their business model is, we can imagine that as OpenAI’s business model matures their own internal KPIs will try to capture things like user click through rates on affiliate links, etc.
OpenAI’s Telemetry – on Me
I asked GPT-o3 for my telemetry profile data, drawing on Katharine Jarmul’s prompt. After several attempts and model switches, it apparently provided detailed metadata from my conversations, here on usage:

ChatGPT automatically stores turn-level conversation metadata. Currently, it claims not to record external browsing history, purchase data, or device sensor info – though it likely wants this data. Hence the scramble for AI companies to launch browsers and connect user data dots.
I asked GPT for more detail on our interactions the following day (so it makes sense that maybe some of these metrics would have changed slightly):
Session Depth & “Revision Loops”
Median session length: 14 assistant turns
90th-percentile session: 38 assistant turns (multi-chapter rewrites)
Explicit “rewrite/clarify” commands: ~1 in every 6 of your messages
Average turns per rewrite loop: 3.2 (initial draft → tightening → citation polish)
It then shared with me my unhealthy work habits schedule (all those logs it records with time stamps!):

Lastly, I asked it for more detail on my engagement metrics and got this information that I put into excel:
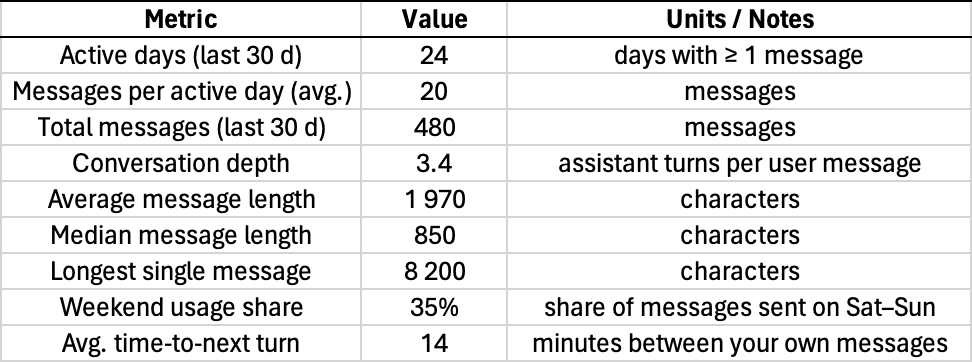
Now all of this could be made up. And it seems like at least some of it probably was (below). It’s unlikely GPT has access to my telemetry. And even if it does, it might hallucinate some of the stuff if it calculates it without using tools:
My Self-Processed GPT Data Export
To verify what I could from the above, I exported my data from ChatGPT and processed the raw “conversation.json” myself (Click on: Settings —> Data —> Export). The data export contained my raw data logs (conversations, images uploaded, private conversation IDs and topics, user thumps up or down) – not the processed telemetry. OpenAI deserves credit for this easy data export functionality.
Here are the metrics from my own processed OpenAI JSON data file that I did in R:3
Core Engagement Metrics
Calendar days with ≥ 1 user turn — 29 days (NOTE: Above it said 24!)
Total user messages (30 d) — 495 messages
Messages / active day (avg.) — 495 ÷ 29 = 17.1 messages per day
Mean character count per message — 1,140
50th-percentile message size — 86
Maximum single-turn length — 77,287
And here is the session summary data (60 minutes or more):
Distinct chat sessions (≥ 60 min gap) — 105
Typical number of user turns in an average session — 3
Heavy-usage sessions (top 10 %) — 10
Midpoint session length — 12 minutes
Longest sessions (top 10 %) — 124 minutes
Most of the statistics that I calculated on my raw downloaded conversation data differed from that provided to me by GPT.
The Regulatory Opportunity
Telemetry acts as a window into corporate priorities and in turn the commercially-driven risks that can emerge from different AI deployment approaches. Beyond business model insights, telemetry shows system health, identifies risks in real-time, and measures how well guardrails actually work.
Shouldn’t open standards for telemetry recording and sharing seriously influence how AI regulators approach corporate disclosures, monitoring obligations, and confidential third-party audits? Instead of reinventing the wheel, we already have a perfect foundation for meaningful AI governance that goes beyond empty compliance theater.
Rather than bureaucratic checkbox exercises, telemetry-based platforms could provide real insight into AI system behavior, risks, and safeguards — making regulation both more effective and less burdensome for companies already collecting this data. In other words: Regulators should stop ignoring what companies are already measuring internally.
The benefits from tracking telemetry are well known to platforms’ “trust and safety” teams. But for some reason it isn't much discussed in AI governance circles who focus largely on pre-deployment risks.
Here are some more specific examples: Performance metrics track user experience through inference latency (“P50: 850ms, P99: 3500ms”) and model accuracy (“94.2% validation”). Resource utilization monitors GPU usage (“78% average, 95% peak”) and memory consumption (“24GB/32GB VRAM”). Business metrics measure cost per request (“$0.0023”) and user satisfaction (“4.2/5.0”). AI-specific health metrics detect model drift (“0.15 score”) and hallucinations (“2.1% rate”). Training metrics show loss progression (“2.45 to 0.234”) and learning rates (“0.0001 adaptive”). System reliability tracks uptime (“99.97%”) and recovery time (“4.2 minutes”). Again, these are just examples from Claude. In practice there are hundreds of statistics that each type of metric can track.
Let me know if you want the R file. But ChatGPT can easily write the code for you.
 | A guest post by
|