


Underappreciated Lessons from DeepSeek
Most AI regulation misses the mark because regulators don't consider the real world context in which AI is deployed


According to Bloomberg, Microsoft and OpenAI are investigating whether (and presumably when and how) DeepSeek’s models were trained using ‘distillation from OpenAI’s models, in violation of OpenAI’s terms of service: “Microsoft, an OpenAI technology partner and its largest investor, notified OpenAI of the activity, the people said. Such activity could violate OpenAI’s terms of service or could indicate the group acted to remove OpenAI’s restrictions on how much data they could obtain, the people said.”
There are several implications, which I hope are not missed in a wave of “China bad!” accusations:
Microsoft (as the cloud provider), not OpenAI, noticed the problem. This is a reminder that the focus of AI safety regulators on the model developer misses the point. Much as auto safety is policed on the roads and flight safety at airports and in the air, not at the factory, and crimes such as money laundering and credit card fraud are detected at banks and credit card companies, AI risks and misuse occur during its deployment. Understanding where those risks can be measured and managed is critical. Cloud providers like Amazon, Google and Microsoft, app stores, payment processors, banks, and performance and security providers like Cloudflare are essential venues for exploring how to police AI misuse. This is going to be even more important as we begin to deploy AI agents.
AI auditing needs to go beyond red teaming of models and instead look at what, in financial auditing, is called adequacy of controls. The COSO framework, which addresses controls, was last updated in 2013. It covers three categories: operations, reporting, and compliance. “Operations Objectives – related to the effectiveness and efficiency of the entity’s operations, including operational and financial performance goals, and safeguarding assets against loss” are what are relevant here [italics mine]. There may be some real value in thinking through how a standard like this needs to be updated for AI auditing, and for auditing of digital services in general.
There is a large amount of irony in OpenAI’s complaint, given that all large language models in the US have also been accused of IP theft and violations of terms of service, including ignoring robots.txt, paywalls, and other attempts to prohibit access by crawlers. We have seen some evidence, yet to be published, that there is already an ecosystem of crawlers exfiltrating data from publishers and reselling it to AI companies, providing them with deniability that they themselves are avoiding the attempts by publishers to protect their data.
There is an obvious solution, which ties into our focus here on disclosures: establish the norm that AI developers disclose the data sources that their models and applications were pre-trained and trained on. This doesn’t mean that they have to disclose them publicly, but they could, for example, be required to disclose them to certified software auditing systems that could attest to their compliance with copyright, terms of service, and so on. There is some precedent for this in the auditing systems like Fossology, Black Duck, and Snyk that companies use to understand the licensing terms of source code that they may obtain and reuse in the systems they build. There are companies like Cinder that appear to be doing some of this for AI, but their services may be more targeted at compliance with terms of service during access to the user-facing apps rather than monitoring API usage.
We mention norms rather than requirements, because they allow the market rather than regulators to decide what information needs to be provided to participants. Much as audited financials are required only for public companies, but it is a norm that banks want to see them for loans and investors for capital investments, it could be the norm for companies to provide information about their data sources; those who failed to do so might be judged more critically by the market because they carried additional risk. This would create a more efficient and competitive AI market.
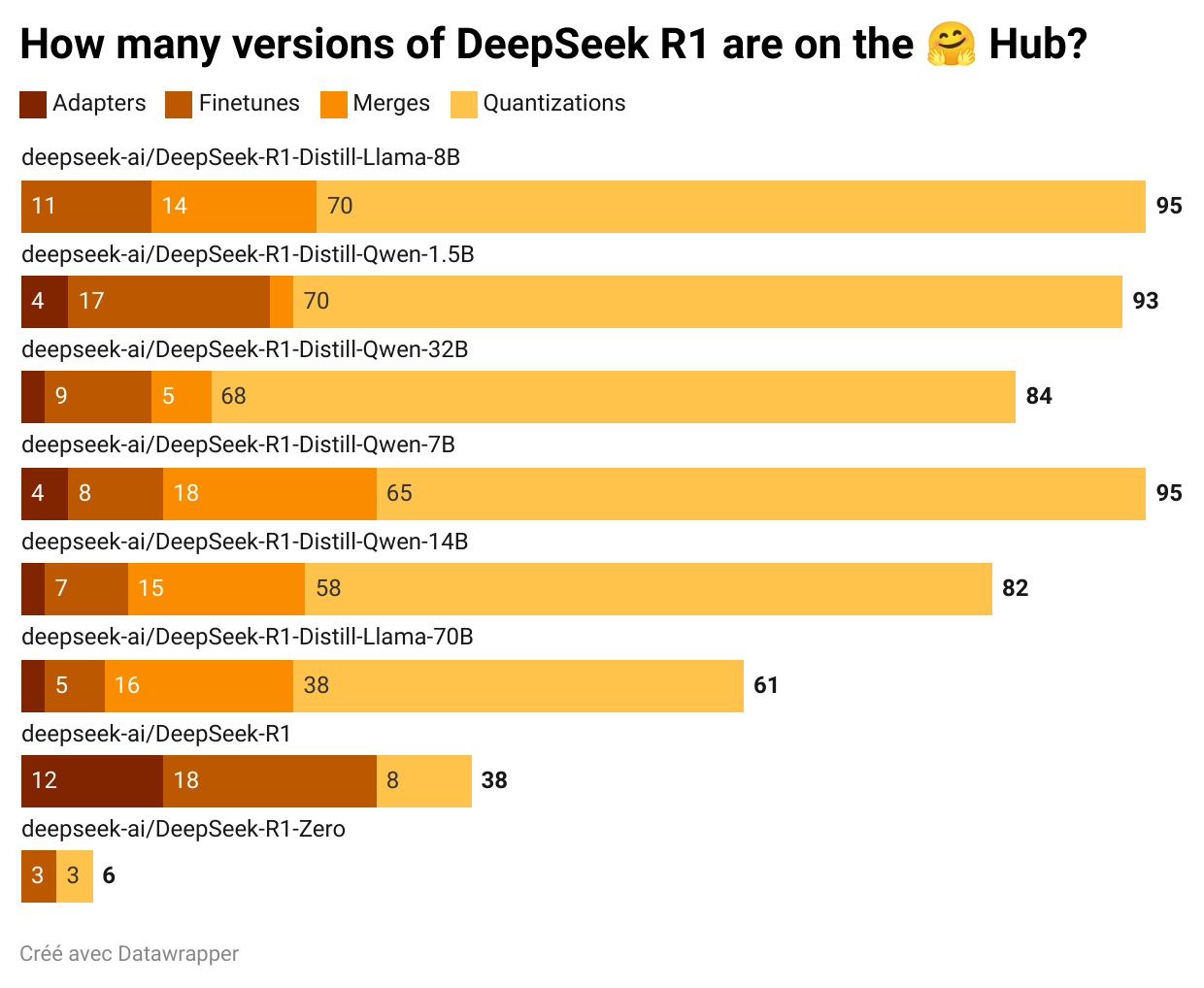
You can make the same point about publishing model weights. The benefits of more open innovation are obvious. Shortly after the publication of the model weights for DeepSeek, there were already hundreds of derivative models available on Hugging Face:
6. Maybe OpenAI and Microsoft’s financial incentives allowed the leak to happen. Bytedance had its access suspended by OpenAI for doing much the same thing mid-2024. The failure to block DeepSeek therefore implies that no new controls — or none that were effective — were put in place to prevent this behavior. But why? One reason could be that the financial incentives were just not there to prevent it – why limit usage of your model if you’re making a ton of (much needed) money from it? And serious money. With the Bytedance infraction: ”TikTok, for instance, was paying nearly $20 million per month to buy OpenAI’s models through Microsoft as of March [2024], according to someone who saw internal financial documents about it. That was close to 25% of the total revenue Microsoft was generating from the business.”
Maybe OpenAI took a calculated risk to allow model distillation, trading off profit against the possibility of enabling competitors. This might have seemed like a safe bet, assuming that any new model would adopt a similar subscription model, and would be sold through the same channels. The risk was instead that the distilled model is given away for free! Open weights and all. And no one seems to have anticipated that its cost for inference would be so low or that a late entrant could become so popular.
Matt Levine archly suggests, without making any accusations, that a hedge fund creating an AI model might well have had a completely different set of economic incentives than either OpenAI or Microsoft. That’s competition for you.
 | A guest post by
|