

Weekly Roundup 9/25/24
Weekly Roundup 9/25/24
Things of note that we've read recently

OK. Weekly it hasn’t been, despite past promises. Which highlights one of the risks we’ve been thinking about. Unless we know what resources have been devoted to them, many of the guardrails offered by AI vendors may amount to little more than good intentions. How thorough has the red teaming been? We don’t know. Are the same guardrails applied to services accessed through third party developers using the API as to the providers’ own hosted services? We don’t know. (Remember Cambridge Analytica, which walked right through this loophole in the social media era.) How well do the guardrails work in other languages and geographies than English? We don’t know. (Remember the Myanmar Massacre, where Facebook’s lack of capability to understand posts in Burmese made mock of the hate speech guardrails it offered in English.)
On to things we’ve seen and thought about in the past weeks:
In his Chartbook newsletter, Adam Tooze picked up this excellent graph from the UN report, Governing AI for Humanity. The graph summarizes a poll commissioned for the report in May 2024 that “sourced perceptions on AI-related trends and risks from 348 AI experts across disciplines and 68 countries.” Despite all the attention paid to existential risk in the media, unintended actions by AI rank at the very bottom of expert assessments of the actual risks. This fits our priors that the focus on these kinds of risks by AI boosters has been a master class in misdirection, which has gotten many regulators focused on the wrong things.
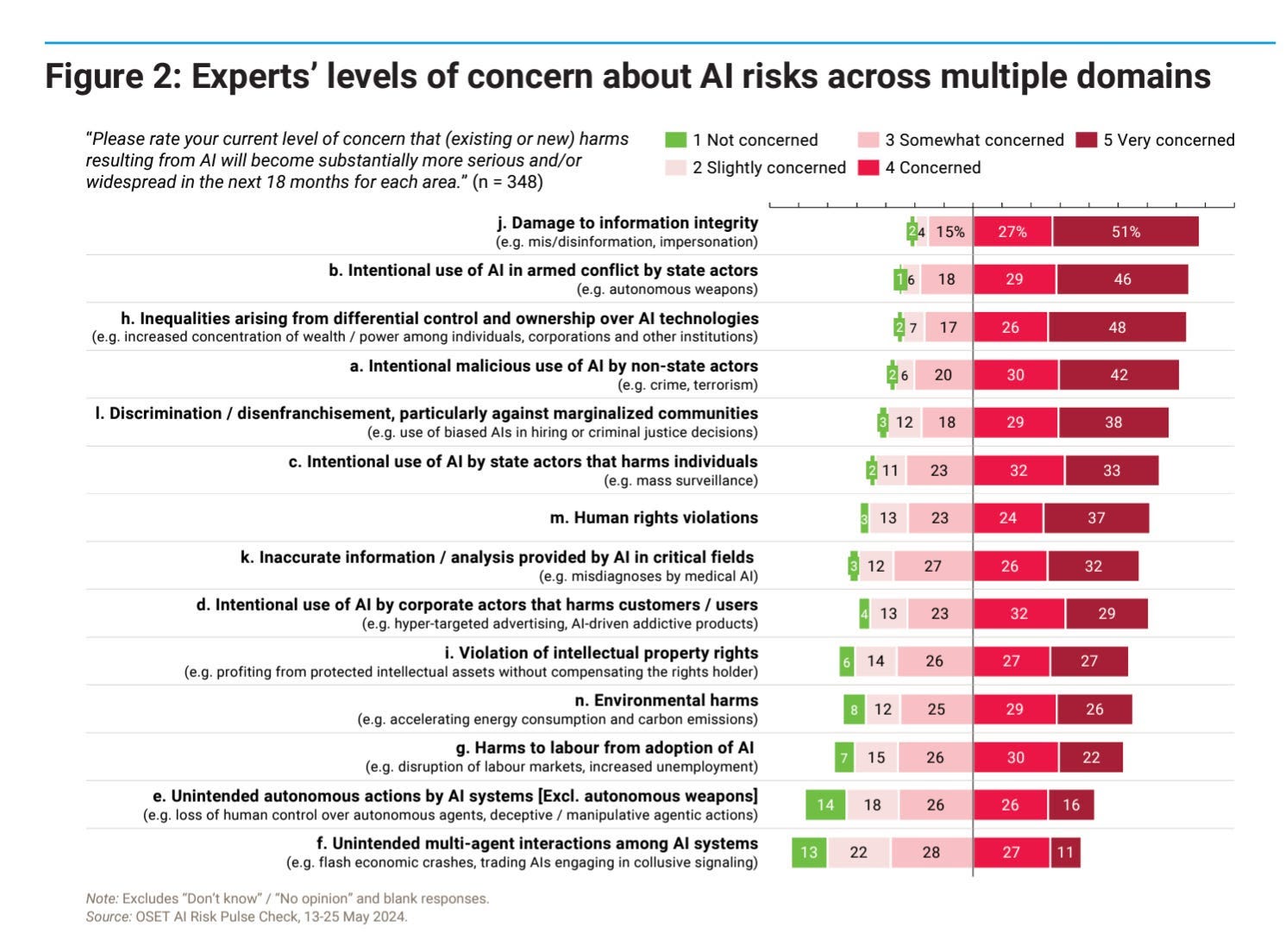
AI governance can’t be left to the vested interests
This is a nice piece by TechCrunch contributor Natasha Lomas that provides a summary of the UN report, and makes much the same point:
“On the one hand, the report observes — quite correctly — that there’s “a global governance deficit with respect to AI.” On the other, the UN advisory body dryly points out that: ‘Hundreds of [AI] guides, frameworks and principles have been adopted by governments, companies and consortiums, and regional and international organizations.’ Even as this report adds plus-one-more set of recommendations to the AI governance pile. The overarching problem the report is highlighting is there’s a patchwork of approaches building up around governing AI, rather than any collective coherence on what to do about a technology that’s both powerful and stupid….
“In recent years, this has included heavy lobbying about the idea that the world needs rules to protect against so-called AGI (artificial general intelligence), or the concept of an AI that can think for itself and could even out-think humans. But this is a flashy fiction intended to grab policymakers’ attention and focus lawmakers’ minds on nonexistent AI problems, thereby normalizing the harmful stupidities of current gen AI tools. (So really, the PR game being played is about defining and defusing the notion of concept of “AI Safety” by making it mean let’s just worry about science fiction.)”
Financial Regulators: Who They Are and What They Do
In pulling on the thread of what AI regulation might learn from financial regulation, we came across this Investopedia guide to the alphabet soup of financial regulators. It is a pointed reminder of John Gall’s famous maxim that “Every complex system that works has evolved out of a simple system that works.” That complex financial regulatory system has evolved over many decades. But even in the early years of AI we are starting out with hundreds of different agencies trying to develop a complex system to regulate it. Perhaps we should instead go back to first principles, and see if we can start with a simple system that works. In our minds, that starts with registration of AIs above a certain level of complexity, and a start at developing the disclosures that would make possible a consistent set of AI audits. We wrote about this a few weeks ago.
Microsoft’s Eureka framework for evaluating and understanding progress in AI
After lamenting the fragmented state of model evaluation, and wondering whether existing evaluations are all measuring the same things, Microsoft offers “an open-source framework for standardizing evaluations of large foundation models, beyond single-score reporting and rankings. The framework currently supports both language and multimodal (text and image) data and enables developers to define custom pipelines for data processing, inference, and evaluation, with the possibility to inherit from existing pipelines and minimize development work. Eureka and all our evaluation pipelines are available as open source to foster transparent and reproducible evaluation practices. We hope to collaborate with the open-source community to share and expand current measurements for new capabilities and models.” This definitely seems worth exploring. If anyone has used it, we’d love your feedback.
Undermining Mental Proof: How AI Can Make Cooperation Harder by Making Thinking Easier, by Zachary Wojtowicz and Simon DeDeo
“Large language models and other highly capable AI systems ease the burdens of deciding what to say or do, but this very ease can undermine the effectiveness of our actions in social contexts. We explain this apparent tension by introducing the integrative theoretical concept of “mental proof,” which occurs when observable actions are used to certify unobservable mental facts. From hiring to dating, mental proofs enable people to credibly communicate values, intentions, states of knowledge, and other private features of their minds to one another in low-trust environments where honesty cannot be easily enforced. Drawing on results from economics, theoretical biology, and computer science, we describe the core theoretical mechanisms that enable people to effect mental proofs. An analysis of these mechanisms clarifies when and how artificial intelligence can make low-trust cooperation harder despite making thinking easier.”