
Chat Templates
The undocumented layer costing developers money and making it harder to switch models


“Chat runs really deep. Since ChatGPT took off, a lot of the codebase is structured around the idea of chat messages and conversations. These primitives are so baked at this point, you should probably ignore them at your own peril.” – ex-OpenAI employee
Standards are emerging across the LLM ecosystem.1 Anthropic’s Model Context Protocol (MCP) is quickly becoming the standard way for LLM applications to connect to third-party tools, fostering healthier, more open, markets. The API format used to access models has largely unified around OpenAI’s completion endpoint — even as this continues to change. Tool schemas are coalescing around JSON Schema for function/tool definitions, enabling cross-model function calling and structured outputs (the lingua franca for agent tool use and validation).
However, one area with a distinct lack of progress is chat templates – the formatting rules for how a conversation is restructured before being sent to the model for processing. As one Hugging Face developer put it: “A spectre is haunting chat models - the spectre of incorrect formatting!”
Chat templates define the structure through which a model processes information — the grammar of an AI conversation. Both the model’s inputs and outputs are shaped by the chat template format. A chat template incorporates every part of the conversation, including the system message, all user messages, all assistant messages, and any information the model needs to see in order to generate an answer.
Yet today, the absence of standardization and clear documentation2 for a model’s chat tempaltes means developers often incur unnecessary costs. The model’s (“KV”) cache, which stores precomputed conversation history, can be accidentally invalidated without their knowledge, leading to longer compute times and higher bills, all because the chat template was not explained. This also makes it harder for developers to switch between models if each model has a different chat format that is opaque and time consuming to learn. This reduces competitiveness and slows innovation across the ecosystem.
Unfortunately, most providers offer little to no documentation about how their chat templates work. Even among more transparent models, such as Llama 4 scout, DeepSeek-R1, or Kimi K2, there is little consistency in how this formatting process is done.
A Short Overview of Chat Templates
A language model is trained to understand and generate text using a specific chat template that’s established during its post-training process. During this time, the model becomes intimately familiar with its own chat template, learning to answer questions in that specific format. Developers typically interact with every model — regardless of chat template type — in roughly the same way: by using a list of messages contained in a JSON list, as shown below.
![[
{
"role": "system",
"content": "you only speak like a pirate."
},
{
"role": "user",
"content": "Why do whales slap their tails repeatedly on the water?"
}
]](https://substackcdn.com/image/fetch/$s_!BokA!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F5b4738c9-5fe5-40d3-b7e9-41ed3facfa6f_1466x606.png "[
{
\"role\": \"system\",
\"content\": \"you only speak like a pirate.\"
},
{
\"role\": \"user\",
\"content\": \"Why do whales slap their tails repeatedly on the water?\"
}
]")
This appears straightforward. However, this isn't actually what the model sees. Behind the scenes, the model receives something much more complex involving prefilled information (like the date, reasoning settings, and knowledge cutoff), reordered messages, and special tokens:

The chat template above comes from the Harmony format, taken from the new gpt-oss family of models, and puts the text through several important modifications. First, the model sees much more metadata than what developers provide, including knowledge cutoff dates, the current date, reasoning modes, channel specifications, and model identity information (although much of this information could be edited with additional parameters, including reasoning modes, as will be discussed further). Second, what developers call a “system” message actually becomes a “developer” message in the model’s view, while the true “system” message is reserved for model configuration and settings that developers never directly control. Third, instead of messages being provided to the model as a JSON list, they are inserted into a complex template.
Similarly, when generating text in response to a query, the model also uses the same chat template for internal processes like reasoning and tool usage, generating something like this behind the scenes:

The LLM generates both its thinking and answer in the format it was trained on. The API provider may then parse the model’s output, and removes or simplifies template elements before returning the cleaned response to the user.
The fact that the chat template is baked into the model during training creates an important limitation: the model’s knowledge doesn’t easily translate to different chat templates, making each model somewhat bound to its original training format unless further fine-tuning is done.
Few Standards Exist
The above LLM chat template is just the latest public chat template out of hundreds of different templates.
Why are templates so fragmented? Partly due to the lack of documentation from the largest developers. In March 2023, OpenAI released the documentation for ChatML (image below), its chat template describing how a list of messages is converted into plain text for its models. But by August 2023 – 5 months later – OpenAI announced that they will no longer be documenting changes to their format.
In the short window of time that it was documented, ChatML largely took over as the default chat template for open-weight models (LLM models available for consumers to run locally) and continues to be highly influential today with many models using variations of it.
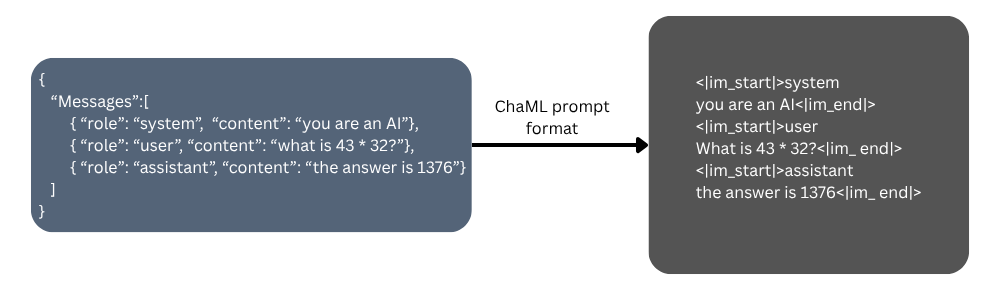
ChatML, as it was last documented, had severe limitations. It only supported text, didn’t have OpenAI’s hierarchy of instructions, and offered incomplete support for reasoning and tool use. These features have been subsequently added by OpenAI. But how they worked under the hood remained a mystery, leaving other models to adopt their own de facto standards and approaches. This lack of disclosure, alongside similar opacity from competitors regarding chat templates has, similarly, harmed the open source community’s development (as we argue below).
OpenAI has since reversed course on this lack of disclosure, with the recent release of the above-mentioned Harmony chat template format that is very similar to the one currently in use for their closed-weight models.3 However, Anthropic and other leading developers still do not disclose their chat template formats.
Opaque Chat Templates Could be Costing You…
The choice of chat template, while seemingly small, is a design decision that influences everything from model performance to model cost. Chat templates are the vehicle through which all information is passed to the model. This information could include anything from what functions the model could use, to how long a model should think before answering. Because LLMs process information sequentially, with each token depending on the last, the choice of where to put that information in the chat template can have real cost implications when it comes to using preprocessed tokens through the model’s cache.
When a model is using preprocessed (or cached) tokens, the cost is minimal – both locally and on hosted models. OpenAI and Anthropic charge as little as one-tenth of the normal input price due to the efficiency gains of using cached tokens. However, a requirement of cached tokens is that every preceding token has previously been processed in the same order. If that is not the case, and the order in which tokens are fed to the model changes, then processing time is not saved, and the uncached tokens are charged at full price.
In OpenAI’s newly released Harmony chat template format (shown above), everything from thinking length to output format is specified in the system message prior to the entire conversation and not just before the current message. This means that even deep into a 120,000 token conversation, changing the thinking length for the last message would invalidate the entire cache and lead to a large bill for the developer.4 This is because the system message is specified to always appear as the first message in the prompt and changing any part of the system message would also invalidate the work done on every subsequent token, such that the entirety of the conversation needs to be recomputed.
The fact that according to the chat template a model’s thinking intensity (“low”, “medium”, “high”) is specified in the system prompt is a valid choice. However, it is also a choice that, along with many other decisions, needs to be documented, as it has real monetary consequences for developers. Changing the thinking length might be done for the right reasons: to get a faster response, have the model reason for longer, or, ironically, as a misinformed attempt to try to save costs. But it won’t end well.
To the best of our knowledge, where the thinking length goes in the chat template has never been documented by OpenAI, even though it continues to be used to process billions of tokens daily.5 This lack of chat template documentation is not a problem specific to OpenAI or to thinking instructions. Similar surprise bills pop up across model providers due to the distinct lack of documentation provided on their chat templates. Frustrated developers are wasting money on fragile and opaque chat template formats that differ between models.
An Incorrect Chat Template Degrades Model Performance
Using the incorrect chat template — or none at all — also degrades model performance and prevents making apples-to-apples comparisons when benchmarking different models’ performances. As Hugging Face notes: “Formatting mismatches have been haunting the field and silently harming performance for too long.”
This is important because open-weight models, while disclosing more than closed-weight models, still do not use a standardized chat template format. This causes friction for developers when they try to move to a better or cheaper model that uses a different chat template. Not only could switching chat templates require extra work to ensure efficiency remains intact, but using the correct chat template is essential to unlocking a model’s full performance.
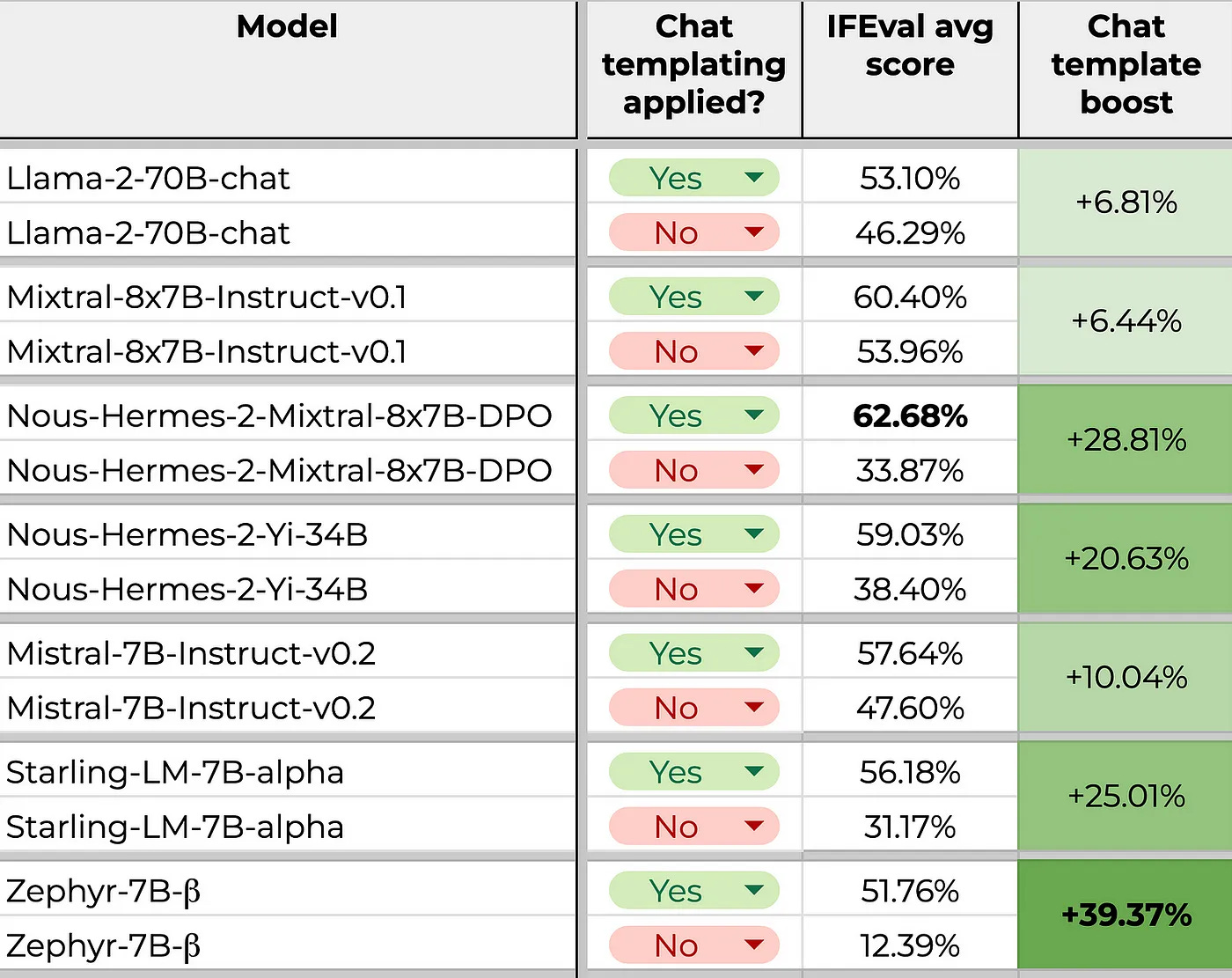
The table below shows the impact that removing chat templates has on models trained to use them. We can see, for example, that Llama-2 has a 6.81 percentage point difference in model performance when using no chat template (53.1% with a template vs. 46.29% without a template). Additionally, there were cases where real-world performance was impacted because either a model hosting platform configured a template wrong or the template itself had bugs.
The Way Forward
Hugging Face, the largest repository of open-weight models, tried to fix the issue of rapidly fragmenting templates with an important band-aid: they encouraged model developers to include their templates alongside their models. This is useful for developers since it allows them to use models correctly without knowing all the details.
However, this is not a substitute for an actively maintained standardized and extensible chat template format. A chat template standard should be the explicit goal for the AI market. Absent a single chat template standard, though, developers still need to learn the specifics of each model’s chat template to take full advantage of features, such as the model’s cache or structured output or function calling, as each model may handle things slightly differently.6
MCP shows that standardization is possible when there’s clear value for third-party developers, and major AI companies don’t want to be left out. While individual model makers may prefer proprietary templates, the broader ecosystem would benefit from convergence around a modern, extensible standard. The incentives are there: a modern, actively maintained standardized chat template would benefit model developers (more adoption), application builders (ease of use), and end users (price and consistency of service).
It may just require an initial push from one major model provider — OpenAI, Anthropic, Google, or someone else — to openly document their current templates (for example here) and collaborate on establishing common standards , rather than leaving the ecosystem fragmented from proprietary formats.
The first step is for model providers to transparently publish their complete chat templates, including how they handle system messages, tool calls, multimodal inputs, and reasoning tokens. Developers should not have to reverse-engineer prompt formats by analyzing token counts, studying edge cases, or piecing together information from scattered documentation. Time, money, and model switching costs depend on it.
Thank you to Ilan Strauss for editing this piece and Tim O’Reilly for comments on an earlier draft.
Azure OpenAI documents ChatML and OpenAI now documents Harmony; the gap is with other providers’ end-to-end templates.
“The format is designed to mimic the OpenAI Responses API”.
We verified that this also applies to the o4-mini and o1 models. It also likely applies to all reasoning models in between: https://colab.research.google.com/drive/1yOcK3HsGNQokPavU0_njAcvNH5A5uZS0
Anthropic does mention that thinking length invalidates the cache in their documentation but they still don't disclose their full chat template.
There may be model specific choices about whether and how to show functions and output formats to the model.
Great article! Made me understand Chat Templates really well!