
Disclosures. I do not think that word means what you think it means.
Disclosures are the language of networks and of markets

"Since the beginning of the current legislative biennium, at least 40 measures dealing with disclosures or disclaimers about the use of AI have been considered in 15 states, according to data compiled by the National Conference of State Legislatures. Such measures have been enacted in five of those states.” – Lexis Nexis State Net Insights,July 16, 2024
Given our work on the AI Disclosures Project, you’d think that would be music to our ears. It isn’t. Most of the proposed legislation focuses on a very narrow vision of disclosures: a warning to the consumer that AI has been used to create particular content, or to make a decision, or that you are conversing with an AI, not a person. This is analogous to mandatory food ingredient labeling, sometimes useful, but barely scratching the surface.

The words we use shape what we can see and imagine. Pushing ourselves to interrogate their meaning can open new ways of seeing and acting.
At the AI Disclosures Project, we are increasingly coming to see disclosures through the lens of networking protocols and standards. Every networking protocol can also be thought of as a system of disclosures. But these disclosures are far more than just a warning label, or a mandated set of reports. They are a form of structured communication that enables independent, decentralized action.
Consider the World Wide Web. You click on a link or type a URL into a search bar. A web page appears. How does that work?

Essentially, your browser uses something called the Domain Name System (DNS) to look up the hostname associated with the URL (substack.com) to find its actual IP address. Substack in turn keeps track of the IP address that it has assigned to its asimovaddendum subdomain. The browser asks for the page designated by the URL (Uniform Resource Locator, in the original language of the web), and the server sends it back.
But as Proust might say, “More slowly.”
The DNS is a decentralized system for mapping a set of unique IP addresses (one per internet-connected device), which are understandable by computers and can be dynamically assigned, onto a system of relatively unchanging, unique names understandable by humans. Both the IP address assignments and the domain names represent a system for formal, decentralized disclosures. Top level domains (TLDs) like .com and .edu are defined by an internet standards organization called the Internet Assigned Numbers Authority (IANA), which then delegates further addresses to Regional Internet Registries (ARIN for North America), which then allocate blocks of IP addresses to ISPs, hosting companies, and other large organizations. When someone registers a domain like substack.com, they’re essentially writing an entry into a centralized registry, which in the case of the .com TLD is maintained by Verisign. The registration establishes ownership and points to “authoritative nameservers” for that domain. These nameservers are run by a marketplace of competing providers. In the case of substack, its nameserver is managed by Cloudflare.
You don’t need to follow all these details to see that there are a lot of rules, standardized information disclosures, and governance infrastructure that make the system work.
At each domain, there are endpoints that allow it to connect to various network services, for applications like email, messaging, the web, or API access.
I could continue the story by describing what information the web browser and the web server exchange in order to share their preferences (such as what kind of user agent it is (for example a browser or a bot), what content type, languages, and encodings the browser will accept, and which the server can provide), and the status codes they exchange to manage the conversation. The actual web page provides all kinds of additional disclosures about formatting that help the browser fetch the additional resources from the server that will help it format the page correctly. And then of course, there may be authentication layered on top of that. Is this user authorized to access this particular page? And so on.
On top of that there are higher level standards that prescribe various behaviors that might be carried out by interacting sites on the internet. One of these is the Robots Exclusion Protocol, which allows web site owners to specify how content on their site can be accessed by “bots” – originally just web crawlers for search, but eventually many more programs, including today, crawlers seeking training data for AI. Similarly, there are various mechanisms for limiting what users can do to access content. Users may be required to authenticate themselves with a valid email address; they may be required to provide a payment credential; the site may place “cookies” on the user’s device to help track usage, to allow personalized advertising or other content, and so on.
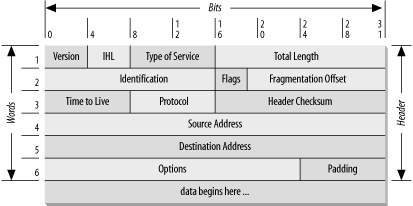
Or we could go lower, and look at the underlying TCP (Transmission Control Protocol) layer, which allows a long and complex message to be broken up into small, easily routable packets, which can be reassembled when they reach their destination (as specified by the Internet Protocol, or IP.) This magic is possible only because everyone on the network follows the same rules, and discloses information in the same formats so that it can be read by routing devices and endpoints on the network.

IP datagram format, from TCP/IP Network Administration, by Craig Hunt
{kind=link}
In an odd way, once you start thinking of networking and communication protocols as a system of disclosures, you also can’t stop seeing other disclosure regimes as a kind of protocol.
It may seem a real stretch to call the rules of the road “protocols,” yet the analogy makes a great deal of sense. For example, posted speed limits, lane markers, crosswalks, traffic lights, and road signs are a protocol for communicating safe and appropriate behavior to drivers, pedestrians, and police.
Similarly, accounting standards are a formalized language (i.e. protocol) for communicating the state of a business to investors, to banks, to tax authorities, to accountants and auditors.
Here are some reflections on what this analogy might mean for AI.
1. Disclosure standards are not imposed; they evolve
One of the most important lessons from every one of the disclosure regimes we have studied is summed up by “Gall’s Law”: “Any complex system that works is invariably found to have evolved from a simple system that worked.”
Early in my career, the lead horse in the race to build a global digital network was a complex 7-layer model called the Open Systems Interconnect, or OSI. OSI was “backed by European telephone monopolies and most governments.” Meanwhile, the internet grew up around a very simple set of protocols developed by an ad hoc community of cooperating researchers and innovators guided by the principle of “No kings, no presidents, no voting. Just a rough consensus and running code.” Internet standards were (and still are) called RFCs – Request for Comment. OSI, rigorous and well thought out from the beginning, became a useful framework for teaching networking theory. The rough consensus and running code of the ad-hoc Internet Engineering Task Force became the foundation of today’s online world.
Accounting standards also evolved rather than being imposed prescriptively at the outset. The road to what we now call Generally Accepted Accounting Principles (GAAP) only began after the 1929 stock market crash made clear the benefit of having all companies follow the same rules.
So too, the familiar rules of the road that we take for granted while driving took decades to be formalized. The first speed limits, road markings, traffic lights, vehicle registration, driver licensing requirements, and private insurance policy all appeared close to the commercial introduction of the automobile, but they weren’t universal in the US until at least the 1940s. Some laws, such as those requiring seatbelts and prohibiting driving while intoxicated, came much later.
In a similar way, AI disclosures (read protocols) need to start with a minimal subset that can evolve, rather than a comprehensive plan that takes every possible contingency into account.
2. Disclosures are a language that enables competitive markets
The simplicity of TCP/IP was able to evolve into the internet complexity we see today because it had an underlying architecture of participation. That is, it was designed in much the way that a road system is designed: it connects multiple points into a network, but doesn’t say whether the endpoint is a house, a factory, a shop, a beach, or a place to pull over and look at a magnificent view. The road system doesn’t specify whether the vehicle is a passenger automobile, a bus, a truck, or a motorcycle. New endpoints can easily be added, and if they become popular enough, the road system adapts to handle the additional traffic. People can add roads (even a dirt road or gravel driveway), companies can build private turnpikes, and the government can build interstate highways. Others build new endpoints, or affordances for different kinds of traffic. For example, while our current road system primarily has destinations (gas stations) for vehicles powered by gasoline or diesel fuel, Tesla was able to innovate with a system of charging stations for its electric vehicles.
The internet, like the road system, doesn’t care so much about the underlying paving. It can run on copper wires, fiber, ground-based wireless networks, or satellites. It doesn’t care what’s at the endpoints or what kind of data is carried in its packets. Other protocols were layered on top of TCP/IP to support different types of traffic going to different types of destinations (HTTP, the Hypertext Transport Protocol, for the web, SMTP, the Simple Mail Transfer Protocol, for email, and many others.)
Contrast this open architecture with the architecture of railroads: centrally controlled, serving a relatively fixed set of destinations with one type of vehicle, requiring payment for each trip, and not easily extensible. We have to ask ourselves whether we want the market structure we are building for AI to look more like a railroad, or more like a road system.
The race for first mover advantage by the large centralized AI providers like OpenAI and their business model of providing AI access through metered API subscriptions suggests a hub and spoke railroad design, while a world of open weight AI models connected by new modes of standardized communication could look more like a road system, or today’s World Wide Web.
The “DeepSeek moment” and projects like OpenR1 make it seem more possible that the winner-takes-all view of the AI future will lose to a more open, competitive model. As a recent Venturebeat article put it: “DeepSeek’s approach to AI development and distribution represents more than a technical achievement — it embodies a fundamentally different vision for how advanced technology should propagate through society. By making cutting-edge AI freely available under permissive licensing, DeepSeek enables exponential innovation that closed models inherently constrain.”
Open source software demonstrates the power of disclosure. It wasn’t just the open protocols of the internet that made its explosive growth possible, but open source web browsers and web servers, email routers and domain name servers, and even easily extensible programming languages. Open source has a profound architecture of participation.
Whether it’s a road system or a network, openness and interoperability lead to richer, more generative systems. This is not to say that future AI monopolies won’t emerge, much as Google’s monopoly on web search, Amazon’s near monopoly on e-commerce, and Meta’s near monopoly on social media were built on top of the open standards of the internet. But they were earned in the marketplace rather than bought in the backroom deals of deep pocketed investors.
When one company is dominant, it can decide on its own disclosures, as each of the major AI companies does today. Each discloses its model capabilities and safety efforts through non-standardized data cards and system cards, privacy policies, codes of conduct, and so on. Each discloses its affordances for developers through its APIs. But if you believe in the future of AI agents, we are heading for a world of cooperating AI systems. This will require rules of the road, a set of standardized disclosures that enable interoperability.
We should ask: What disclosures will make it possible to build a distributed AI market, where permission to innovate isn’t given by those holding all of the cards, but is somehow intrinsic to the market itself?
3. Disclosures are a foundation of “the rule of law”
Networking standards have a rigorous conception of what a well-formed packet, formatted document, or API endpoint looks like. That consistency is essential to a network’s operation. At a higher level, though, the guiding good of the internet was interoperability. The notion that anyone using the same protocols could participate, that there were no gatekeepers, was a fundamental part of what made the internet such a fertile ground for innovation. “No kings, no presidents, no voting. Just a rough consensus and running code.”
In a different way, accounting standards are also based on a firm notion of what good looks like: investors are provided with the information needed to make decisions. A GAAP or IFRS based P&L statement, balance sheet, or cash flow statement is supposed to accurately reflect the underlying business. It tells us, for example, whether a company is optimizing for profitability or for growth, whether the company is increasing or decreasing its costs or margins, and how effectively it is run. It does not tell investors whether or not this is a good strategy, but it discloses the information (in conjunction with the management’s narrative) that investors can use to decide for themselves whether it is or not.
Even rules of the road are based on a notion of the good. We are asked to slow down before a curve or in a school zone, to wear seat belts, or not to drive while intoxicated because society has learned through difficult experience that this makes the roads are safer for everyone. We follow the same rules because the system works better when we do. Disclosure of speed limits doesn’t just help drivers all follow the same rules, though. It is also the basis for enforcement of a regulatory regime (policing) with penalties for misbehavior. Everything from speed limits to bans on driving while intoxicated, to systems of identity tracking via both driver’s licenses and vehicle license plates are built on a foundation of disclosure.
Disclosure is also an essential defense against abuse of power. Until laws were introduced in the 1940s to require local municipalities in the US to post road signs every time the speed limit changed, speed limits could be used to extract fines from unsuspecting motorists. Sometimes, the simplest disclosures can be the most powerful.
The notion that everyone adheres to a shared definition of the good can also be described as the “rule of law,” which is often cited as a critical foundation of the market economy. This does not mean that every country, or even every local jurisdiction, follows all the same laws, but that the laws that exist are known and are reliably followed. And it means that to the extent that laws differ, mechanisms exist to bridge differences to the extent that people in different jurisdictions want to trade or otherwise cooperate.
The notion of “good” referred to here is not absolute, but is a pragmatic set of choices leading to some kind of local optimum. In many cases, it is a Nash equilibrium. That is, it is an agreed-upon stable state that provides incentives for all parties to make the same set of consistent choices. A rough consensus and running code.
There is more than one possible Nash equilibrium. For example, countries have adopted different conventions for which side of the road is used for a given direction of travel. Despite past experience and training, drivers are highly incentivized to adopt the local equilibrium.
This is not to deny the existence of good and evil, truth and falsehood, better and worse, but to note that many of the conventions that we adopt as a society are neither. They are, as thinkers from George Soros to Yuval Noah Harari have observed, true or false only to the extent that people share a belief in them. The idea of a Nash equilibrium introduces the further nuance that only some sets of shared beliefs represent a stable state, where adherence to the rules is an optimal outcome most of the time. Most social systems that work (i.e., systems based on agreements between people rather than the laws of physics) work because they represent a stable equilibrium.
These equilibria are generally discovered over time through a process of trial and error, as described above. They can also be lost over time.
We believe that the rise of market power by gatekeepers such as Amazon, Apple, Google, Meta and others is challenging the stable equilibrium that has shaped the operation of the internet for the past three decades. We all have the sense that the internet in which everyone was equal but anyone could rise to prominence has given way to a system in which, as George Orwell put it in Animal Farm, “All animals are equal but some animals are more equal than others.” And we are beginning to understand the cost of that market power. We all have the uneasy experience of remembering how social media feeds lured us in with the promise that they would show us updates from our friends, but gradually shifted to showing us “suggested content” and ads. We remember when Amazon marketplace search showed us the best product at the lowest price, and now shows us what merchants are willing to pay Amazon to put up top. We remember when the top results in Google search were almost always what we were looking for, rather than what someone paid to have us see. But we don’t have any clear sense of when or how that changed.
The notion of what is good to the developer of applications from these companies is implemented by a set of internal operating metrics that the company uses to manage its systems. Changes in these internal metrics could tell us what the company is actually optimizing for. Unfortunately, accounting standards have not kept up with the transition from industrial age companies where knowing about a company’s physical inputs and outputs is sufficient to understand the business. Most of the internet giants are software systems transforming intellectual inputs and outputs into products that are often given away for free and monetized only indirectly. The failure of accounting standards to come to grips with this change makes much of the business invisible to scrutiny and accountability. This is even more true with AI.
As we wrote in our paper “Algorithmic Attention Rents: A Theory of Digital Platform Market Power,”
Like their predecessors, LLM systems internalise and centralise a vast marketplace of human knowledge and experience. As presently implemented, AI systems pass through neither attention nor remuneration to the providers of content used to train the model. As in present systems, human inputs are regarded as raw materials that can be appropriated by the developer of the system. If history is any guide, control over these raw materials by frontier AI platforms will eventually lead to the quest for a business model that allows for the extraction of monopoly rents.
Looking back at what we know now about present platforms, we can only wish there had been a disclosure regime that would have shown us the state of these systems when their creators were focused on serving their users and other ecosystem partners, and thus told us when and how they began to turn from that path to extract self-serving economic rents. Much like their predecessors, these frontier AI systems are managed by metrics whose details are known only to their creators and disclosed to the outside world only via generalities and sporadic, often self-serving data points. The time to establish rules for disclosure of operating metrics for frontier AI systems is now.
Consider how, in what limited and inconsistent disclosures we see today, a feature like the persuasiveness of AI systems is considered a risk to be managed down. Yet in AI systems with an advertising based business model, it is likely to be considered a feature to be dialed up to eleven. Right now, AI services are expensive to deliver, so optimizing for addictiveness, as so many current internet applications do, is less of a risk, but that could change.
Disclosures can play a key role in encouraging a stable equilibrium between the needs of the developers, users, and suppliers that make up the AI market. There’s a relevant lesson from accounting standards: when reporting is regular and consistent, it is possible to compare present and past results and future projections. This is not at all the case with reporting about how AI systems are being managed – or for that matter, with reporting about the current generation of internet applications from companies like Amazon, Google, Meta, and TikTok.
So we have to ask ourselves, “What does good look like for AI?” What does it look like now, when AI model and application developers are competing to attract users by serving their needs? Based on lessons from the past, what might it look like when they achieve outsized market power?
In one sense, the entire effort of training AI models, increasing alignment, reducing hallucination, and demonstrating success on various kinds of benchmarks is a quest to answer what good looks like. But in contrast to the shared definition of “good” that exists in accounting standards, rules of the road, and in networking protocols, everyone in AI is playing by a slightly different set of rules. This shows up in the inconsistent ways that companies disclose information about how their models work, how much they disclose, or how truthfully they work to meet the benchmarks. This is much like the state of accounting during the Roaring 20s, before the crash and the introduction of today’s accounting standards.
Market participants also lack clarity about their relationship to the current generation of AI systems. The sources of training data are treated as a trade secret, even though this data may have been acquired by violating the rights of others. Rules for whether or not user input will be used for training data is inconsistent and hidden behind changing terms of service.
There is another lesson from accounting that provides a ready answer. All disclosures need not be made public; they might be shared with trusted intermediaries (perhaps even software intermediaries) who can then reveal it only to those with the right to know, such as the copyright holder. Nor does this need be done in the 20th century way, with auditors sitting in the secure private offices of those being audited. Technologies such as those developed by the non-profit OpenMined can enable privacy preserving audits of AI systems. Anthropic’s Clio, a tool for understanding how its users are interacting with its AI systems, also uses privacy preserving technology.
Right now, content creators are trying to preserve their rights with the version of locked gates and a bar on the door. This is an indication of lawlessness rather than the rule of law. As is usually the case in the face of such a lack of clarity, torts highlight the problems with new technologies and immature markets. Numerous lawsuits have already been filed, and we should take them as evidence of areas requiring disclosure and eventual standardization of best practices.
There is also encouraging technical work in this area. For example, Creative Commons is exploring whether it is feasible to create a replacement for the Books3 database (which contains many pirated books) with a book database explicitly designed for training AI while preserving copyright information. Such a database could be used to power an equivalent to YouTube’s Content ID, the system Google uses to remunerate music rights holders for the use of their music despite it being mixed into billions of public videos without prior authorization.
We’re still in early days, and it is too early to standardize reporting of the operating metrics that guide AI systems. Nonetheless, it is essential to begin the work of understanding and sharing best practices on how these systems are currently managed, to track how management metrics change over time, and to identify types of data disclosure that would enable economic activity, in the way that YouTube Content ID has become an important element of sharing ad revenue generated by the video creator economy.
Rules of the road for cooperating AIs
If we want a world where companies and individuals don’t have to erect barriers against AI to preserve their privacy or intellectual property from AI developers, a world that respects the rights of content creators as well as the needs of AI model developers, we need a system of disclosures and means for enforcing them.
If we want a world where everyone, not just AI model developers and those building on top of their centralized networks, is able to innovate and to offer their work to others without paying a tax to access centralized networks, we need a system of disclosures that enables interoperability and discovery.
If we want a world of AI agents that interoperate not only with each other but with humans, with earlier generations of web technology (including not just web services APIs but the AI use of screen scraping), and with real world services, AI agents will need to identify not only themselves but those who set them in motion.
AI agents bring into focus the rationale for many disclosures mandated in other regimes. Who does this agent represent? Are they authorized to do what they are attempting? Who is responsible if something goes wrong? And we must also be able to answer the question that Robin Berjon asked so pointedly: do they have a “fiduciary duty” to the user or are they beholden to the company that created them?
In short, we need to stop thinking of disclosures as some kind of mandated transparency that acts as an inhibition to innovation. Instead, we should understand them as an enabler. The more control rests with systems whose ownership is limited, and whose behavior is self interested and opaque, the more permission is required to innovate. The more we have built “the rule of law” (i.e. standards) into our systems, the more distributed innovation can flourish.
In their paper Infrastructure for AI Agents, Alan Chan et al note:
“Increasingly many AI systems can plan and execute interactions in open-ended environments, such as making phone calls or buying online goods. As developers grow the space of tasks that such AI agents can accomplish, we will need tools both to unlock their benefits and manage their risks. Current tools are largely insufficient because they are not designed to shape how agents interact with existing institutions (e.g., legal and economic systems) or actors (e.g., digital service providers, humans, other AI agents). For example, alignment techniques by nature do not assure counterparties that some human will be held accountable when a user instructs an agent to perform an illegal action. To fill this gap, we propose the concept of agent infrastructure: technical systems and shared protocols external to agents that are designed to mediate and influence their interactions with and impacts on their environments.”
Anthropic’s Model Context Protocol (MCP) is a step in the direction Chan and his co-authors outline. But we have a long way to go. In short, the fact that we are in the early, immature stage of the development of a consistent disclosure regime for AI is another way of saying that we are in an immature stage in the development of an environment where AI agents can successfully operate.
Getting good answers to the questions asked throughout this essay should matter to everyone who believes that markets are most efficient in the absence of large asymmetries in information and power, that the spread of knowledge is the key to progress, and that the goal of innovation is not just for a few to profit at the expense of others but to build a better world.
In short, disclosure should not be seen as a mandate from regulators, but an active topic for computer science research, AI deployment, and business model innovation. It is how we will build both interoperable AI and the systems by which we can observe and manage its behavior. That word: disclosure. It does not mean what you think it means.
 | A guest post by
|
A good essay. In the past you have espoused companies creating ecosystems around their products, yet the trend seems to be predation instead. How do we go in the direction you outline in this essay, given the current state of AI and corporate goals?