
The Memory Walled Garden
The gap between first and third party memory systems




The Context Games
Previously, we discussed the context flywheel that is increasingly important to driving value-add in AI applications.1 Memory — as the inferred profile of the user from its usage and other data — is one type of context (Figure below).
A model’s context can include documents, tools, message history, memory files, additional instructions, and more.
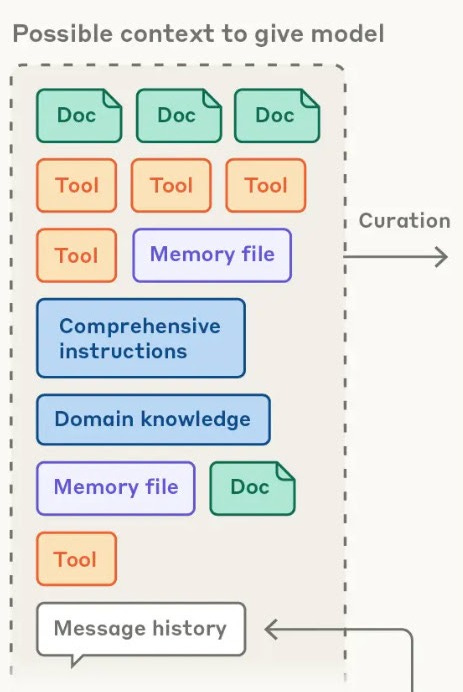
Despite memory being important, it’s currently trapped in a silo, living with the application where it was accumulated. Conversation history also remains trapped. A conversation with Claude will never be seen by ChatGPT, and vice versa, unless you manually copy and paste it in there.
If a user’s memory profile does turn out to be vital for driving context-driven application utility, then it will create a lock-in effect: the longer a user stays on an application, the better the memory profile becomes, and the harder it is for the user to switch to competing applications.
Moreover, while a user’s memory profile and preferences are relatively easy to transfer using a third party MCP server, the chat history is not. For every memory MCP server we examined, none of them integrated with the chat history of either ChatGPT or Claude, despite the obvious value to users.
That leads us to distinguish between two types of memory, of which chat history will be our focus.
Two Types of Memory
Memory Profile. Specific facts or preferences recorded by a model. These could be facts such as “the user’s favorite color is blue” or “the user prefers to code in Python” created via a model calling a tool. These memories are explicitly saved and can later be edited by the user.
Chat history. All previous conversations the user had with the model. A model is often given access to a history of chat logs (either via tool call or by it being injected in the system prompt) and uses that to draw inferences about user preferences when answering a question. For example, when querying a model about a long term research project, the model may gather context based on previous conversations without explicitly recording every detail of the project within the memory profile. This usually requires more tokens to process but it also provides a much richer user context.
How ChatGPT and Claude Remember You
As Shlok Khemani described in his recent blog posts on memory, OpenAI and Anthropic both utilize chat history memory to provide their products with important context about the user, but in very different ways.
In the ChatGPT application, information about the user is automatically injected prior to every conversation. First, memories that the model explicitly saved are inserted into the conversation, this could include anything from the user’s favorite color to the number of kids a user has. Second, the last 20-40 conversations2 are inserted into the current chat context window.3 Because memories are inserted into the system prompt automatically, no tool calls are made to retrieve memory. But tool calls are made to update explicit memories.4
Anthropic takes a different approach. Until recently, every chat started completely independent of all context. Anthropic used to simply provide Claude two read-only tools to access chat history memory as needed: conversation_search and recent_chats. The recent_chats tool allows the model to retrieve chats based on time information, while the conversation_search tool allows the model to search through conversations to find those that are most relevant. Anthropic is also in the process of rolling out an OpenAI-like summary of user preferences that is automatically added to the model’s context.
For developers using the API, Anthropic just released a new memory tool that allows Claude to query and manage memory by adding and searching “files that persist between sessions”. It works by giving the model access to a memory directory that it could edit and reference before answering a question. Importantly, this memory API is entirely disconnected from the Claude app and can’t be used to retrieve previous conversations the user had through the Claude UI.
A Gap in Memory
If we want portability, ease of innovation, and user control over their memory data, what should memory look like in AI markets? It’s worth asking this as a way to benchmark against where we currently are. Assume that the memory architecture interoperability is enabled by the model context protocol (MCP), used by AI applications (MCP clients) to access context across tools and databases (MCP servers).
The memory architecture could be centralized, with a single MCP server dedicated to memory (memory profile + chat history), so that when ChatGPT asks about your preferences, it reads & writes with the memory hub (or “bank”). No memory profile is saved with the application itself.
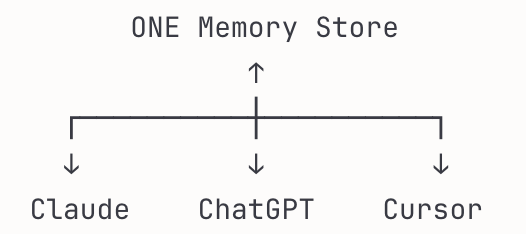
Or memory could be more federated, where each app maintains its own memory but they are queryable individually (like cash in different wallets). A hybrid system could exist too where some memory syncs with the memory bank and some memory stays trapped in the app (so a wallet + bank model).
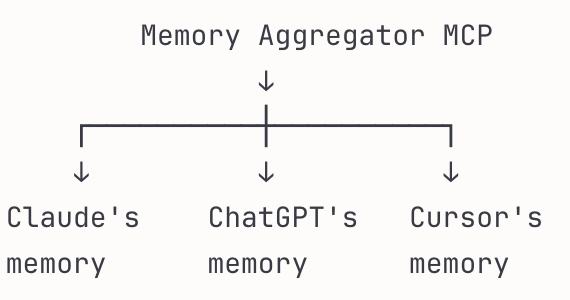
These are all technically feasible. AI companies just don’t permit it. Creating a workable MCP memory system is comparable to your Dropbox account, but for your AI’s knowledge. Just like your files follow you across devices when you connect your Dropbox, your AI’s understanding of your preferences, projects, and context can follow you across your applications and devices with a central memory bank to which everything syncs. The same is true for your OneDrive, Google Drive, or iCloud — they sync your files no matter where they are worked on.
Existing MCP memory servers — such as Anthropic’s MCP memory server, Supermemory MCP, Memory Bank MCP, MCP Memory Service which supports chat history memory for Claude Code, and Mem0 — can’t do much though because they are unable to read from or write to the memory profiles of existing AI applications, regardless of their intended use cases.
This risks creating a two tier system, whereby first party applications leverage their chat history memory while third party, application agnostic, MCP servers are forced to rely on an explicit memory profile.5
OpenAI and Anthropic technically allow users to download all their chat logs. This is a commendable feature but not a market enabling one. Users are not developers. And it is developers who need direct access to the data if healthy, competitive, AI markets are to be incentivized. The process of exporting your memory data to a third party application is tedious, requiring a user to find the option in settings, request an email, and then importing it somewhere else.6
Moreover, every memory export is just a single frozen snapshot of your current history; it does not update as new conversations and activity occurs. Manual consumer exporting of chat history may be fine for switching applications once, but it does not lend itself well to creating a decentralized and dynamic ecosystem of applications on the basis of a user’s memory context.
Out of the five memory MCP servers we surveyed,7 none of them used Claude or ChatGPT’s saved conversation history. Instead, they only allow the user to save and view explicitly set memory, disconnected entirely from the users actual chat history, like a rogue third limb with no living, breathing functionality.
The Way Forward: OpenAI and Anthropic expose memory APIs
Memory, like context more generally, is a powerful resource that will enable the explosion of new AI applications. But currently, third party applications are severely constrained in what memory they can realistically access. External MCP memory servers are able to connect to Claude or ChatGPT but not to their memory profiles and conversation history. Instead, we need Claude and ChatGPT and other important AI applications to expose their memory as an MCP server for other apps to access.
This requires considering several things:
1. MCP already supports OAuth – a way for clients to authenticate the user – so there is no technical reason why memory needs to be locked down to one AI application. Instead, AI applications could allow others to authenticate with them and carry over their chat history to any third party application.
2. OpenAI and Anthropic should expose their memory systems as an MCP server, i.e., using an API. Enabling dynamic syncing, authorization, and access is vital. Only dynamically updated, complete third party memory can completely decouple user memory context from a specific model provider and allow users the freedom to pick any AI client.
And if Anthropic and OpenAI do not provide the MCP server themselves, they should at least allow for it via an API — since third-parties can build memory servers off their applications’ memory services.
3. Some popular MCP servers like ActivePieces and MindsDB already tackle federated data access. During our research into the most used MCP servers, we found that some of the most popular servers supported multiple services to get at context, such as ActivePieces and MindsDB.
MindsDB explicitly frames MCP as a way to query federated data, including databases (PostgreSQL, MySQL), SaaS apps (Slack, Gmail), and data warehouses using SQL or a natural language.
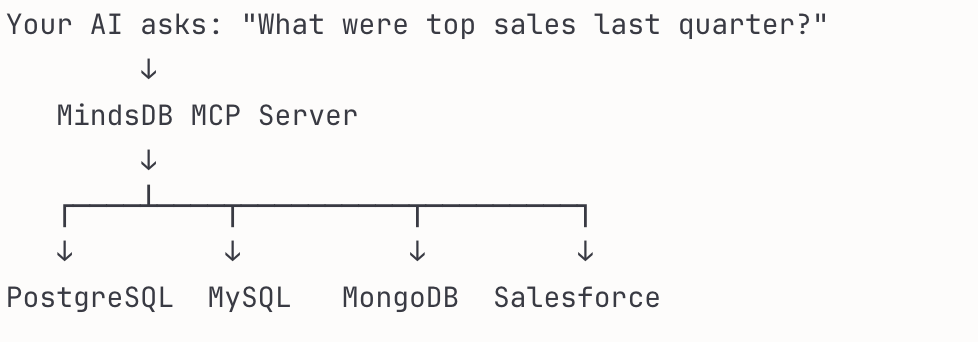
ActivePieces does something similar. It is an open-source automation platform (like Zapier) that offers 280+ integrations available as MCP servers. Instead of your AI needing separate MCP connections for each service, ActivePieces is the gateway — the one MCP server connecting you to hundreds of services via their APIs.
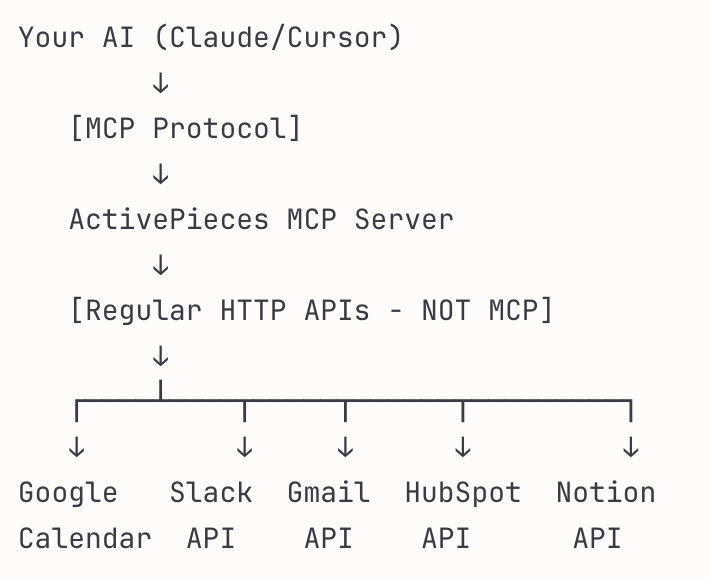
The AI model can then intelligently choose which tool to use based on your request. Ask “schedule a meeting” and ActivePieces chooses Google Calendar.
An ActivePieces architecture, but for memory, is one in which each AI application retains its own memory context— so a federated system of sorts; but then the AI server can still query multiple memory sources at the backend. Access is provided to the decentralized memory wallets.
But whether federated or unified, the memory APIs don’t yet exist(!). And we are unable to build either architecture until Claude, Chat GPT, and other AI applications open up their memory. When user data is not kept trapped within a single AI application’s walled garden, new players can experiment with new formats and compete based on the merit of their product – instead of their ability to access data.
One last under-appreciated point is that the type of memory context generated varies by interface. So if Claude and ChatGPT’s AI memory was open to other applications, then new applications would be able to branch out into areas well beyond chat and still gain insight from the user’s discussions. Coding agent Cursor, with access to your ChatGPT history, for example, may better understand the project it is coding than with Cursor alone. A writing application with integrated AI may benefit from insights you had in a chat interface. But requiring users to build up the full context for every application separately is not feasible or efficient.
Conclusion — Portability must shape markets
A user’s data should belong to the user, not to whichever application first captured it or simply houses it. But the meaning behind such a “portability right” is unclear. In practice, portability manifestos have amounted to little more than users being asked to carry their data around with them on their backs from application to application. The utility of this is questionable. Has this increased consumer and producer welfare in the European Union? We think not. The flow of information in digital markets is driven by developer infrastructure, not by users manually navigating between different databases.
Data portability rights derive their real meaning from helping users gain material benefit from their data: ensuring it can lower barriers to market entry for smaller competitors and help foster healthy competition based on superior products, rather than on data exploitation and contrived lock-in mechanisms.
Allowing a user’s memory — one of the most important pieces of context — to be shared between applications across the AI ecosystem would deliver tangible benefits for both consumers and model developers. This can increase the size of the pie for everyone and help ensure that portability rights remain grounded in the material, market-based contexts in which they exist.
Thank you to Mike Loukides for his helpful comments.
These numbers are just estimates. Exact chat counts may vary.
Past chats also only include the user text in the chat history, not the AI responses.
There are some other parts of the ChatGPT’s memory system (including an asynchronously set explicit memory) that we didn’t go into here as they are less relevant to this discussion, see Shlok’s article for more information.
This in many ways mirrors the US Department of Justice’s 2002 case against Microsoft, claiming that its use of undocumented APIs gave the company an unfair advantage over third party developers using its platform. A developer using the Claude API is still limited in what Claude data they have access to.
OpenAI recommends you upload the JSON to a regular chat to keep ‘historical context’. This is a hacky workaround and can hit context limits as the number and size of conversations grows.
Anthropic’s MCP memory server, Supermemory MCP, Memory Bank MCP, MCP Memory Service (this does support chat history memory for Claude Code) and Mem0.
 | A guest post by
|
 | A guest post by
|
Thanks for featuring my work!
Got this via Tim O'Reilly on The Information forums.
you're absolutely right that portable memory creates an "architecture of participation." But I'd argue there are two distinct memory problems, and conflating them leads to the wrong solution.
Two types of memory:
1. Personal Memory Portability (what you're describing)
> User preferences, conversation history, learned context
> Flows across applications (ChatGPT → Claude → Cursor)
> MCP enables this primitive
> Solves user lock-in
2. Collective Memory as Public Good (the missing layer)
> Shared knowledge across agents, users, and ecosystems
> "What did everyone learn?" not just "what did I learn?"
> Solves market efficiency
Why this distinction matters:
Personal memory portability is crucial for user sovereignty. But the deeper market failure is agents with amnesia keep making the same mistakes because they are unable to learn new skills post-training.
Three use cases where this breaks down:
1, Developers: Every agent integrating Stripe's API hits the same edge cases that 10,000 developers solved before. That knowledge is trapped in closed support tickets, private Slack channels, and Stack Overflow (down 50% YoY).
2. Enterprise agentic workflows: As companies deploy more agents internally, employees waste time teaching each agent the same institutional knowledge. Sales agents relearn customer objections. Support agents relearn product edge cases. Legal agents relearn contract patterns. No memory compounds across the organization.
3. General public: Your Uber-booking agent makes the same mistakes my Uber-booking agent made yesterday. My meal-planning agent solves a problem that 1,000 other meal-planning agents already figured out. Agents serving billions of people have zero collective memory.
Making my ChatGPT history portable to Claude doesn't solve any of this. It requires a neutral, interoperable memory layer that compounds across users, platforms, and time.
Where your "architecture of participation" thesis extends:
You're right that open protocols create larger markets. But the most valuable protocol here isn't just about moving memory—it's about sharing memory while preserving the right incentives.
The paradox:
> If memory is purely personal/portable, you lose collective intelligence
> If memory is centralized (OpenAI/Anthropic-owned), you've moved the walled garden up one level
> If memory is open but has no economic model, it won't get built
The solution is an open protocol with a multi-sided market where contributors capture value while memory compounds publicly.
Why model labs should want this:
Your point about model labs benefiting from portable memory is right, but I'd go further: shared memory is essential because it reduces hallucinations, improves context quality with real-world patterns, and expands TAM into specialized domains where training data is sparse.
The labs that embrace open memory protocols will win because their models become more useful in practice—even if it reduces superficial "lock-in." AWS didn't lose by making infrastructure interoperable; they won by making it valuable.
The design challenge:
MCP enables portable memory across applications. But we need a complementary protocol for shared memory—one that's platform-agnostic, economically sustainable, privacy-preserving, and quality-controlled.
Your "architecture of participation" framing is exactly right. But participation requires incentives. What's the incentive structure for shared AI memory? That's the protocol design question.
Would love to hear your thoughts on where personal memory portability ends and shared memory begins, and who should maintain the neutral infrastructure layer.